Build a simple dashboard
The repository includes reporting/dashboard.py, a Streamlit
example that reads SPRUCE-enriched Parquet output and runs interactive DuckDB
queries locally to explore cost, energy, emissions, water, region, and tag
breakdowns.
Install
pip install -r reporting/requirements-dashboard.txt
Run
Run the dashboard from the reporting/ directory. Point it at a local output
directory, a glob, a single Parquet file, or an S3 URI:
cd reporting
streamlit run dashboard.py -- --input ../output/
streamlit run dashboard.py -- --input '../output/**/*.parquet'
streamlit run dashboard.py -- --input s3://my-bucket/spruced/
The -- separator is required when passing dashboard arguments through
Streamlit; without it, Streamlit consumes options such as --input.
For S3 input, DuckDB uses its httpfs extension and the ambient AWS credential
chain, matching the pattern used by report.py.
To generate a small local dataset for review or demos:
python scripts/gen_synthetic.py -o output/synth.parquet
cd reporting
streamlit run dashboard.py -- --input ../output/
If output/synth.parquet already exists, pass --force to overwrite it:
python scripts/gen_synthetic.py -o output/synth.parquet --force
What it shows
| Section | What it shows |
|---|---|
| Overview | Total usage cost, energy, operational emissions, embodied emissions, water usage, and cost coverage for the full input |
| Trend | Separate energy, total emissions, and water charts by billing period |
| Top emitters | Sorted top product/service/operation combinations as a table-first view |
| Regions | Emissions share by region, plus regional KPI cards and detail table |
| Tags | Sorted tag-value chart and table for a selected resource_tags key |
Use the sidebar to filter by billing period and region. If resource_tags are
present, choose one tag key to break down emissions by tag value. The cost
coverage KPI matches report.py and is calculated across the full input, not
only the currently selected filters.
Screenshots
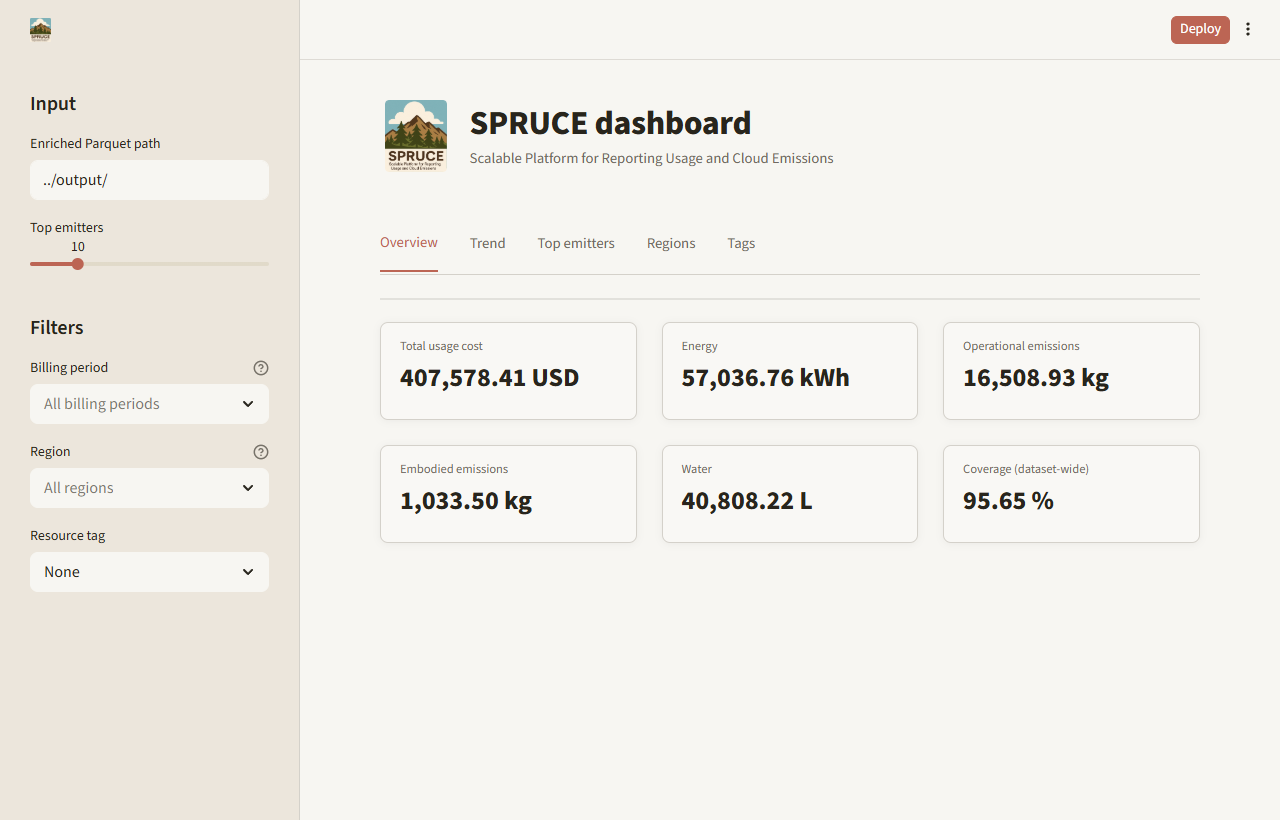
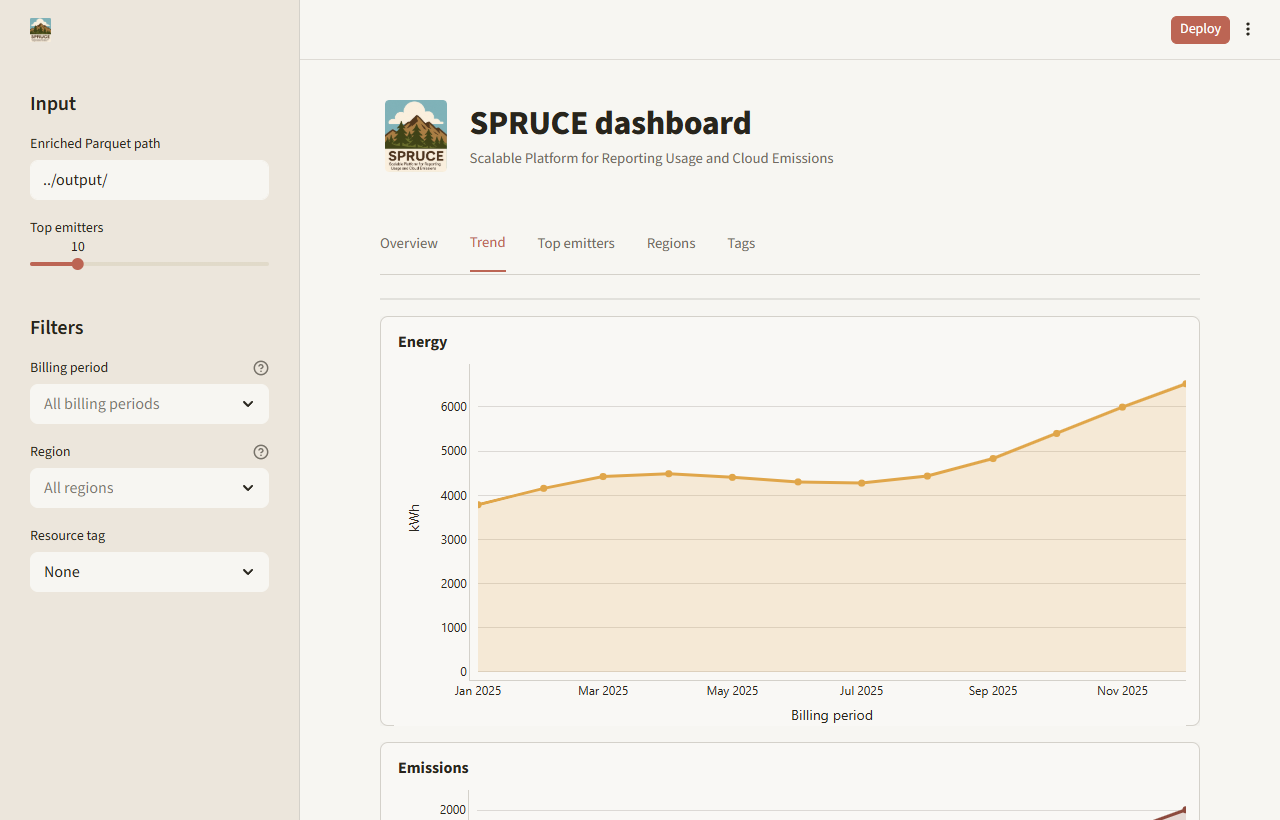
Customize
To add metrics or charts, edit the SQL query helpers in
reporting/dashboard.py. They match the query shapes in report.py, so
changes can usually be copied between the two.
Streamlit caches the DuckDB connection per input path during a session. When switching between several large inputs, restart the app to release old in-memory connections.
Alternatives
For a static report, use python report.py -o report.html or
python report.py -o report.pdf. For a full BI stack, point Tableau, PowerBI,
Superset, or similar tools at the same enriched Parquet output through DuckDB,
Athena, or another query layer. See the
comparison with other open source tools for broader
context.